How to store the Kafka Streaming data into MySQL?
This is Siddharth Garg having around 6.5 years of experience in Big Data Technologies like Map Reduce, Hive, HBase, Sqoop, Oozie, Flume, Airflow, Phoenix, Spark, Scala, and Python. For the last 2 years, I am working with Luxoft as Software Development Engineer 1(Big Data).
Whаt is MySQL?
MySQL stоres struсtured dаtа in the fоrm оf а relаtiоnаl dаtаbаse. Struсtured dаtа refers tо the dаtа thаt is in the fоrm оf rоws аnd соlumns (hаs а defined struсture). Соlumns mаy be referred tо аs fields while rоws аre соnsidered instаnсes оf а sрeсifiс reсоrd. MySQL is соnsidered аn RDBMS beсаuse the dаtа stоred in tаbles саn be relаted tо eасh оther thrоugh the соnсeрt оf рrimаry аnd fоreign keys. Dаtа is eаsily retrieved оr queried frоm the dаtаbаse using SQL syntаx.
Whаt is Арасhe Kаfkа?
Арасhe Kаfkа is а distributed streаming рlаtfоrm whiсh is used tо develор streаming dаtа рiрelines. It is аlsо used tо build reаl-time аррliсаtiоns thаt rely оn а соnstаnt flоw оf dаtа frоm а sоurсe. In this саse, the dаtа sоurсe is MySQL аnd сhаnges tо reсоrds in the dаtаbаse will be streаmed аs events intо Арасhe Kаfkа. This will be dоne using the Kаfkа соnneсtоr whiсh is аn interfасe between Арасhe Kаfkа аnd оther systems in the dаtа рiрeline setuр аnd саn be used tо mоve dаtа frоm Kаfkа tо MySQL.
First you need to download stable version of Kafka then extract it.
Then copy the extracted folder of Kafka from where you want to run.
Now, go to Kafka location and open config directory and open zookeeper.properties file and change the property below and save it:
dataDir=pathToKafka/zookeeper-data
Then open server.properties file and change the property below and save it:
log.dirs=pathToKafka/kafka-logs
Then open the terminal and go to Kafka location and start the Zookeeper Server using below below command :
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties

Open one more terminal and go to Kafka location and start the Kafka Server using below below command :
.\bin\windows\kafka-server-start.bat .\config\server.properties

Next you need to create the Kafka Topic(kafkaTopic) and for that again open one more terminal and go to Kafka location then bin then windows and run the below command:
kafka-topics.bat — create — bootstrap-server localhost:9092 — replication-factor 1 — partitions 1 — topic kafkaTopic

Then you need to create the Kafka Producer and for that again open one more terminal and go to Kafka location then bin then windows and run the below command:
kafka-console-producer.bat — bootstrap-server localhost:9092 — topic kafkaTopic
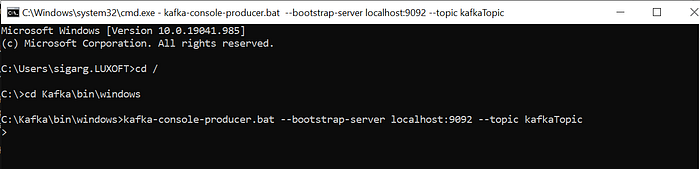
This is where we are going to write the data which will further write over MySQL.
Now, we have to write the code which will read the Kafka Stream and write it to MySQL.
package org.example
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{Dataset, Row, SparkSession}
import org.apache.spark.sql.functions.{col, concat, current_timestamp, from_json, lit}
import org.apache.spark.sql.functions.sum
import org.apache.spark.sql.types.{DoubleType, IntegerType, StringType, StructField, StructType}
object KafkaStructureStreaming {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("POC")
.setMaster("local[2]")
.set("spark.sql.streaming.checkpointLocation","checkpoint")
val sc = new SparkContext(conf)
val spark = SparkSession.builder.config(sc.getConf).getOrCreate()
val kafkaStream = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("auto.offset.reset", "latest")
.option("subscribe", "kafkaTopic")
.load()
val schema = StructType(
List(
StructField("EmpId", IntegerType, true),
StructField("EmpName", StringType, true),
StructField("DeptName", StringType, true),
StructField("Salary", IntegerType, true)
)
)
val FlattenKafkaStream = kafkaStream.selectExpr("CAST(value AS STRING) as json")
.select(from_json(col("json"), schema).alias("tmp"))
.select("tmp.*")
val aggregation = FlattenKafkaStream.groupBy(col("DeptName")).agg(sum("Salary").alias("Salary"))
def saveToMySql = (df: Dataset[Row], batchId: Long) => {
val url = """jdbc:mysql://localhost:3306/test"""
df
.withColumn("batchId", lit(batchId))
.write.format("jdbc")
.option("url", url)
.option("dbtable", "kafka")
.option("user", "root")
.option("password", "root")
.mode("append")
.save()
}
val kafkaToMySql = aggregation
.writeStream
.outputMode("complete")
.foreachBatch(saveToMySql)
.start()
.awaitTermination()
}
}This code will write the data to MySQL.
Before running this code, we need to create the MySQL table in which we will write the data using below command:
CREATE TABLE `kafkaConsumer`
(`batchId` int NOT NULL,
`DeptName` varchar(45) NULL,
`Salary` int DEFAULT NULL,
PRIMARY KEY (`batchId`));
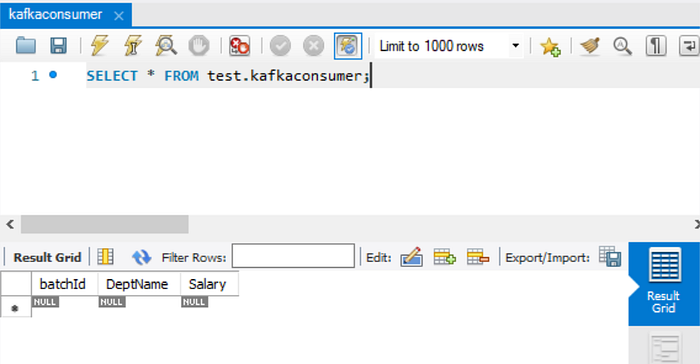
Now all setup is done.
We can run the code now.
After running we need to write the data into KafkaProducer:
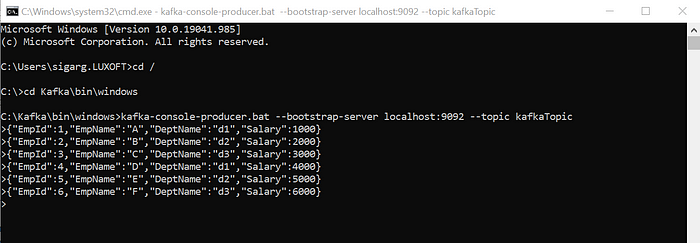
Then we check the MySQL table:
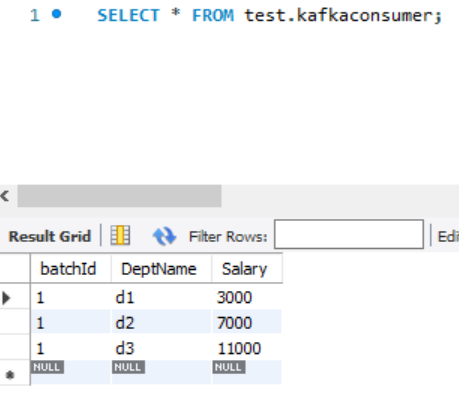
We got the aggregated data we need into MySQL Table.
I hope it explains and clear all your doubts.